🧩What is RLHF? Why It Matters to Every Business in 2025
🧠 Reinforcement Learning from Human Feedback (RLHF) is the core technique powering today’s most advanced AI systems — including the GPTs you’re already using (knowingly or unknowingly).
But this isn’t just about AI models — it’s about how businesses learn, adapt, and optimize based on human input.
📈 Here’s the simple truth: Businesses that don’t evolve their systems to learn from real human feedback in real-time — will be left behind!

✍️Why RLHF Matters:
AI is Now the Frontline of Customer Experience!
Whether it’s chatbots, virtual assistants, or recommendation engines — these systems must understand nuance. RLHF teaches them that.
Instead of just rules-based systems, RLHF enables your AI to learn what actually works by integrating real human feedback, not just cold data.
✅ It’s How Machines Learn Human Values
This is crucial for brand voice, ethics, trust, and alignment.
For example: → A GPT trained with RLHF knows not to respond in a tone that misrepresents your brand.
→ It understands the human subtleties behind customer satisfaction or dissatisfaction.
✅ Turns Feedback Loops Into Profit Engines
RLHF is more than an AI term — it’s a business operating principle:
Collect human signals (clicks, reviews, conversations)
Optimize response models
Continuously refine based on feedback
You can apply this same RLHF model to:
Product development
Marketing funnels
Sales training
Customer support
✅ It’s the Blueprint Behind Prescriptive Intelligence
At a high level, RLHF is what separates predictive systems from prescriptive ones — systems that not only see trends but also suggest optimal next steps based on real human preference.
✅ Authority Layer You Can Trust
We act as a bridge, not a broker. You’re backed by a clear intelligence layer built on verified interest and feedback.
✅ Your Competitors Will Be Using It (Silently)
Whether it’s jets, yachts, machinery or niche services—RLHF lets you act on data others miss.
✅ Final Angle for SEO + Strategic Positioning:
RLHF is the new real-time feedback loop — at scale!
It’s how modern businesses train their systems to think, respond, and win.
🧠An Array of AI-Enhanced Resources
Bridge the gap between data, feedback, and commercial outcomes using RLHF-powered intelligence.
🛠️ RLHF Signal Reports
- Get distilled human-in-the-loop insights for your product category
- Identify friction points your competitors miss
- Gain clarity on why buyers hesitate or abandon deals
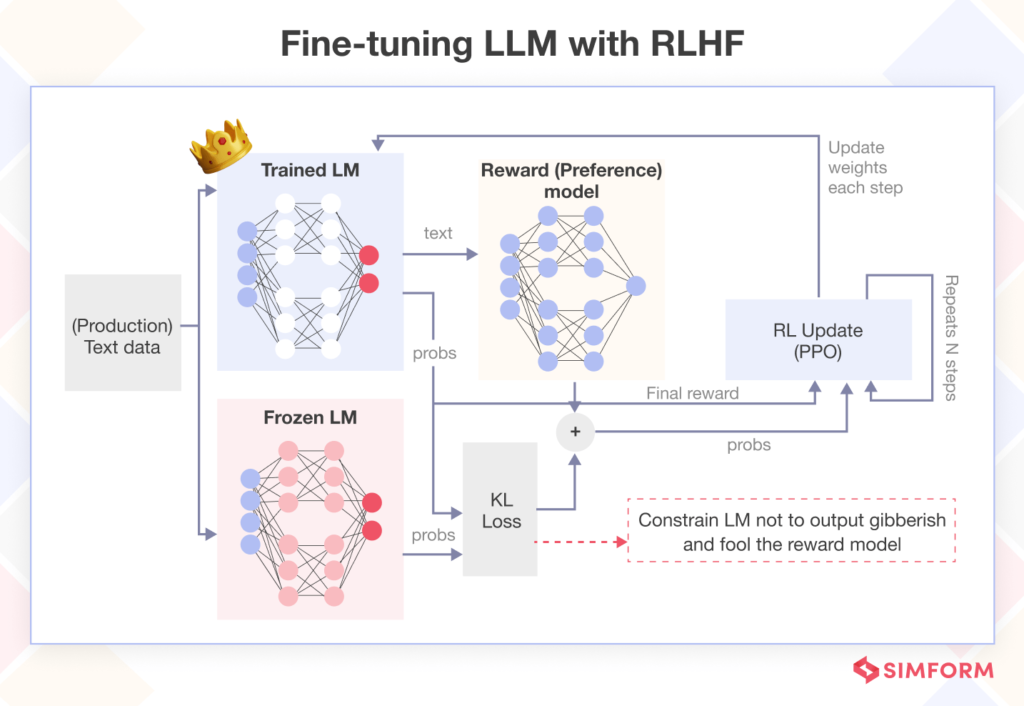

🧬RLHF Training Sets
Build your own fine-tuned GPT based on real buyer feedback
Adapt messaging per region or sector based on responses
Continuously improve lead flow quality over time
🔁 Join the RLHF Network Trusted by Strategic Buyers & Sellers
Stay in the Loop with Everything You Need to Know.